
Naive Bayes
Naive Bayes
这次实验主要使用朴素贝叶斯算法做分类,除了分类外贝叶斯算法还可以用来做回归。使用朴素贝叶斯的一个前提条件是各个事件都是独立的,这一点在实际应用中是必须要记住的
贝叶斯模型
在贝叶斯模型中我们对信度(beliefs)比较关心,这个从贝叶斯方式来说可以解释为概率。对于某一事件\(A\),我们通常有这个 事件\(A\)的先验知识。比如下雨这一事件,我们知道在夏天发生的可能性要大于冬天,这就是一种先验知识。 对于事件\(A\)和事件\(X\),贝叶斯公式如下: \[ P( A | X ) = \frac{ P(X | A) P(A) } {P(X) } \propto P(X | A) P(A)\;\; (\propto \text{is proportional to } ) \]
上面公式中的\(P(A)\)表示先验概率, \(P(A|X)\)表示后验概率。更深入可以参考 Christopher M. Bishop 写的 Pattern Recognition And Machine Learning
虽然说朴素贝叶斯理论不是太难,介绍到这里也差不多可以了,但是贝叶斯算法在模式识别中应用是非常广泛的。个人觉得有一句话说得非常有道理:
如果想要学习知识,读;如果想要理解知识,写;如果想要掌握知识,教
所以下面再多写些例子,这样也可以让自己更好的理解这部分的知识点
抛硬币例子
抛硬币是我们在教科书上接触的最多的一个例子了,只要合适基本都用这个来举例,所以这里也用这个经典的例子。 现在假设我们不知道抛出一枚硬币后不知道出现正面和反面的概率分别是多少,然后看看如何在实验中通过观察到的数据来做出推论。 我们使用\(H\)和\(T\)来分别表示某次试验中出现正面、反面。现在有个比较有趣的问题是随着试验次数的增多,我们所做出的推论会有哪些变化呢? 或者更准确一点来说,后验概率是如何随着观测数据的变化而变化的。 下面借助 python 来帮我们完成这一实验
1 | %matplotlib inline |
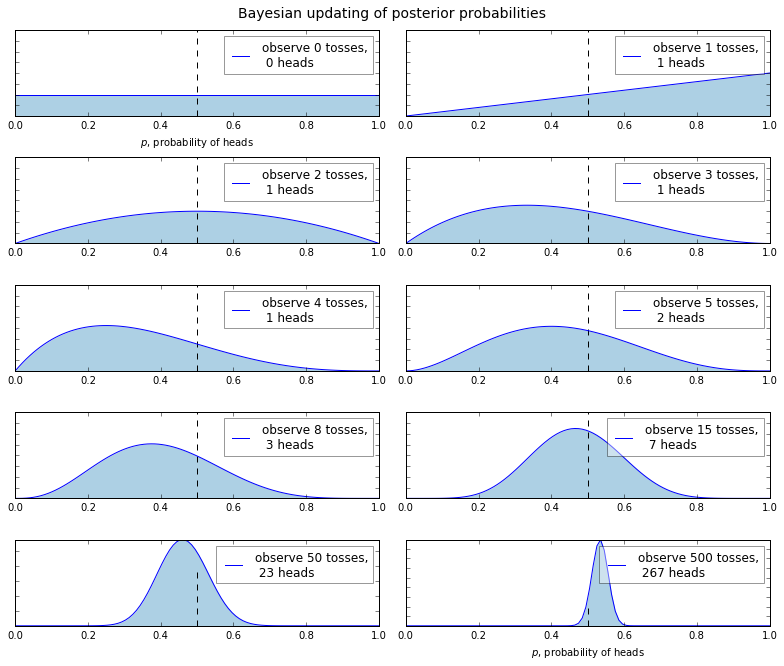
曲线表示的就是后验概率,曲线的宽度和我们推论的不确定性是正比的。从上面的实验结果图可以看出,随着观测数据(试验 次数)的逐渐增多,后验概率也发生了相应的偏移,最终的概率值逐渐逼近\(p=0.5\)(使用虚线表示),并且曲线的宽度逐渐变窄, 也就是不确定性增大。仔细观察曲线发现,曲线的峰值并不总是在\(p=0.5\)处出现,其实这也是在情理之中,因为我们假设 了不知道先验概率是多少。实际上如果我们的观测数据比较奇葩,比如 8 次试验,只有 1 次是正面,那我们得出的分布就会出现 很大的偏置(峰值偏离 p\(p=0.5\)比较大)。或许我们会有这样的疑问,给出一个试验数据,比如说上面举例的 8 次试验,为什么 估计正面或者反面的概率不是一个具体的数值(eg. \(\frac{1}{8}\)),而是给出一个分布出来呢?其实这也很正常,给出这个 试验,我们又有多大的把握确定其概率就是\(\frac{1}{8}\),而不是其他的呢。所以上面的曲线就是表示有多大的把握确定概 率\(p\)就是某一个值的,这也就是贝叶斯的一个比较重要的地方。
说了这么多,看看朴素贝叶斯算法在老师给的数据集上的表现如何吧。下面只给出实现朴素贝叶斯算法的关键代码,具体细节 的地方就省略了。
1 | def nb(train, p_e, test): |
以下数据是朴素贝叶斯算法应用在有 1000 多个情感数据集中的表现,其实比 KNN 的要差。对不同情感预测的相关系数如下:
| anger | disgust | fear | joy | sad | surprised |
|---|---|---|---|---|---|
| 0.1859 | 0.1765 | 0.3034 | 0.2451 | 0.2283 | 0.1490 |